
用 LangChain 實作出簡易版 RAG
此文紀錄使用 LLama3 + Langchain + llamacpp + Chroma 組合成一個簡單的 RAG !
整體 RAG 架構圖:
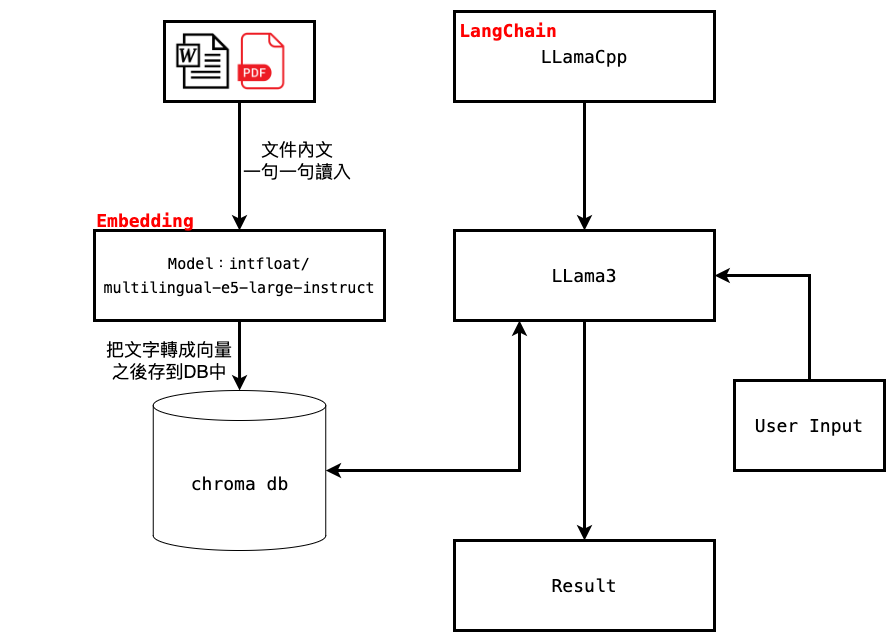
- 先讀入我們補充的資料
- 利用語言模型幫我們做 Embedding 幫我們的字串分析並轉成向量
- 把轉換後的向量存去向量資料庫
- 利用 LangChain 的 Library 內的 LLamaCpp 啟動我們的 LLama3 模型
- 我們就能輸入問題
- 拿到問題後他會嘗試去資料庫找相似的答案
- 經由 LLama3 回答問題
Code:
import os
import sys
import time
import chromadb
from dotenv import load_dotenv
from langchain.chains import ConversationalRetrievalChain
from langchain.text_splitter import RecursiveCharacterTextSplitter, TokenTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders import Docx2txtLoader
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain_community.llms import LlamaCpp
from langchain.chains import RetrievalQA
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# 讀取資料 pdf, docs, docx, txt ...
documents = []
# Create a List of Documents from all of our files in the ./docs folder
for file in os.listdir("docs"):
print(f'Now Load:{file}')
if file.endswith(".pdf"):
pdf_path = "./docs/" + file
loader = PyPDFLoader(pdf_path)
documents.extend(loader.load())
elif file.endswith('.docx') or file.endswith('.doc'):
doc_path = "./docs/" + file
loader = Docx2txtLoader(doc_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
text_path = "./docs/" + file
loader = TextLoader(text_path)
documents.extend(loader.load())
# 讀取並切割字串 (RecursiveCharacterTextSplitter 這一段有3種不同的切割方式有興趣的同學可以自己去看一下 Langchain 的 library)
start_time = time.time()
# Split the documents into smaller chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=250, chunk_overlap=50)
documents = text_splitter.split_documents(documents)
end_time = time.time()
splitter_time = end_time-start_time
# 把剛剛切割的字串使用 ntfloat/multilingual-e5-large-instruct 模型去作 Embedding ,我這邊是選擇用 CPU 可以用 GPU 會比較快
start_time = time.time()
# Embedding Sentence-transformer Model
model_name = 'intfloat/multilingual-e5-large-instruct'
model_kwargs = {'device': 'cpu'}
embedding = HuggingFaceEmbeddings(model_name=model_name, model_kwargs=model_kwargs)
end_time = time.time()
embedding_time = end_time-start_time
# 把轉好的資料放到 Chroma DB 裡,這邊是使用簡易版直接放到 memory 中
start_time = time.time()
# setup Chroma in-memory, for easy prototyping. Can add persistence easily!
client = chromadb.Client()
# Create collection. get_collection, get_or_create_collection, delete_collection also available!
collection = client.create_collection("all-my-documents")
persist_directory = Chroma(client=client, collection_name="all-my-documents")
# Convert the document chunks to embedding and save them to the vector store
vectordb = Chroma.from_documents(documents, embedding=embedding, persist_directory=persist_directory)
vectordb.persist()
end_time = time.time()
vectordb_time = end_time-start_time
# 啟用 LLama3 並使用 LLamaCpp 一樣可以設定參數
# Main LLM
llm = LlamaCpp(
model_path="/root/LLM-models/Llama3-8B-Chinese-Chat-q8_0-v2_1.gguf",
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
verbose=False,
n_gpu_layers=100,
n_batch=1600,
n_ctx=8000,
f16_kv=False,
temperature=0.7,
use_mlock=True,
use_mmap=True,
vocab_only=False,
)
# 設定 模版 等等... 並設定會去 DB 找再回傳給 LLama3 回答
# With Langchain Model
# This controls how the standalone question is generated.
# Should take `chat_history` and `question` as input variables.
template = (
"Combine the chat history and follow up question into "
"a standalone question. Chat History: {chat_history}"
"Follow up question: {question}"
)
prompt = PromptTemplate.from_template(template)
# create our Q&A chain
pdf_qa = ConversationalRetrievalChain.from_llm(
llm=llm,
condense_question_prompt=prompt,
retriever=vectordb.as_retriever(search_kwargs={'k': 6}),
return_source_documents=True,
verbose=False,
)
# 原版模型用來跟有 LangChain 來比對回答
# Original Model
template = """
Question: {question}
Answer:
"""
prompt = PromptTemplate(template=template, input_variables=["question"])
# Create an LLMChain to manage interactions with the prompt and model
Ollm = LLMChain(prompt=prompt, llm=llm)
yellow = "\033[0;33m"
green = "\033[0;32m"
white = "\033[0;39m"
chat_history = []
print(f"{yellow}---------------------------------------------------------------------------------")
print(f'Init Time:')
print(f'Splitter_Time:{splitter_time} seconds')
print(f'Embedding_Time:{embedding_time} seconds')
print(f'Vectordb_Time:{vectordb_time} seconds')
print('Welcome to the DocBot. You are now ready to start interacting with your documents')
print('---------------------------------------------------------------------------------')
while True:
query = input(f"{green}Prompt: ")
if query == "exit" or query == "quit" or query == "q" or query == "f":
print('Exiting')
sys.exit()
if query == '':
continue
# 有搭配找尋 chroma DB 在回答的 LLama3 回答
result = pdf_qa.invoke(
{"question": query, "chat_history": chat_history})
print(f"{white}Answer: " + result["answer"])
print("=====================================================")
# 原版 LLama3 回答
Ollm_answer = Ollm.invoke(query)
print(Ollm_answer, '\n')
print("=====================================================")
# 紀錄功能
#chat_history.append((query, result["answer"]))
最後就能實作出簡單的 RAG 了簡單吧!!
有興趣的同學還能串接網頁搜尋的 API 不過我看都要錢所以我就沒接了QQ
